Treinamento IA
Introdução
O treinamento da IA via YOLOv8 é um processo fundamental para capacitar modelos de detecção de objetos em imagens. Utilizando conjuntos de dados anotados, o algoritmo ajusta os pesos das suas camadas de convolução para aprender a identificar padrões e características dos objetos. Ao final do treinamento, o modelo resultante é capaz de detectar objetos com alta precisão em tempo real, sendo útil em diversas aplicações de visão computacional.
Metodologia
1. Preparação dos Dados
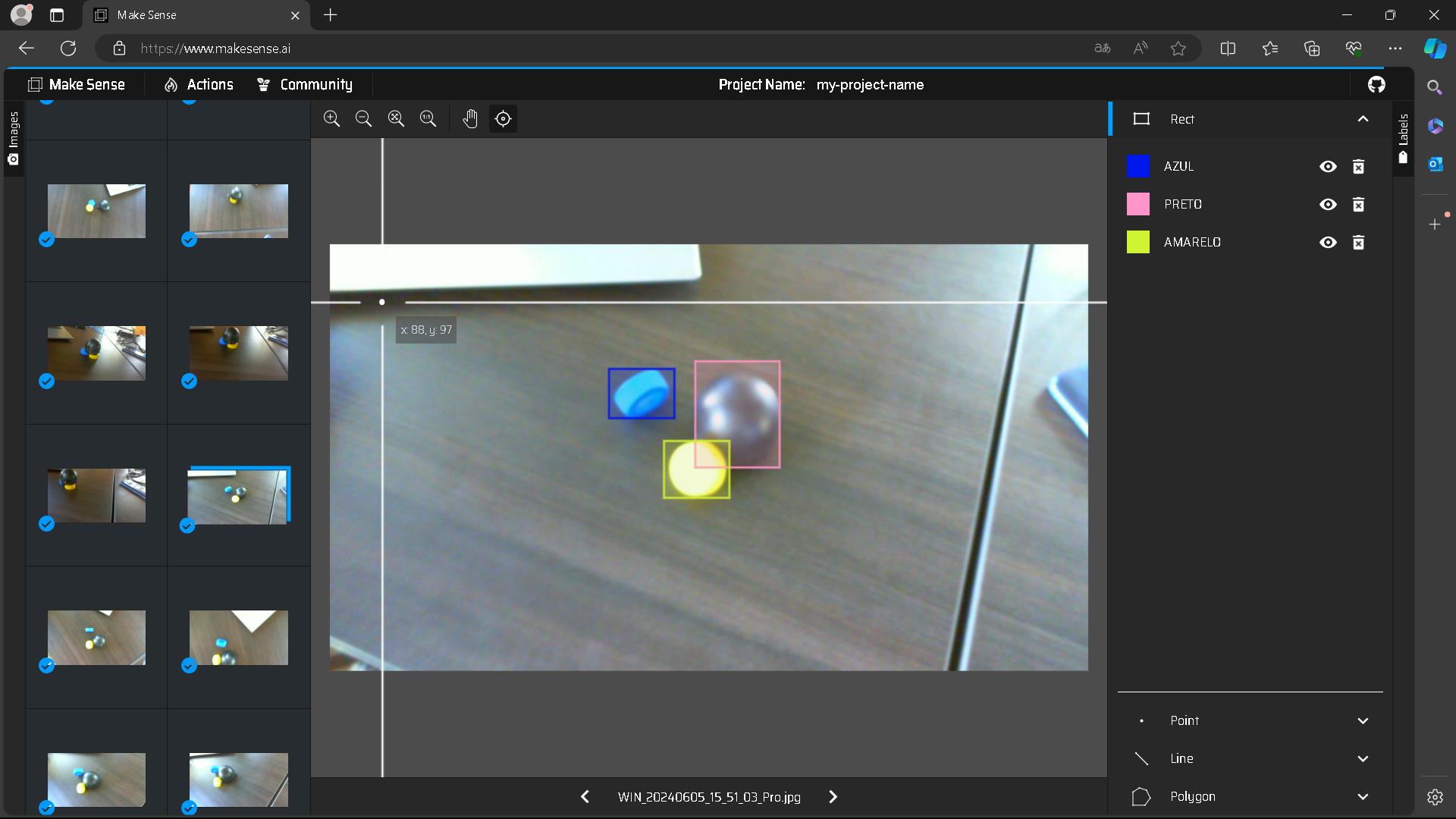
- Seleção do conjunto de dados: Utilizamos um conjunto de dados, ao todo foram tiradas 188 fotos de três objetos diferentes e rotulando-as com o MakeSense, como podemos observar na Imagem 1. Vale destacar que as peças utilizadas para o treinamento não são as peças finais do projeto.
2. Treinamento do Modelo
- Para o treinamento, após realizar todas as rotulações foi desenvolvido o arquivo de configuração de treinamento do modelo onde é separado o diretório de treino e validação com os nomes das classes e o código de treino com a quantidade de epochs definido.
3. Avaliação do Modelo
- Para avaliar as métricas o YOLOv8 gera métricas ao decorrer do treinamento, Imagem 2, para avaliação do modelo.
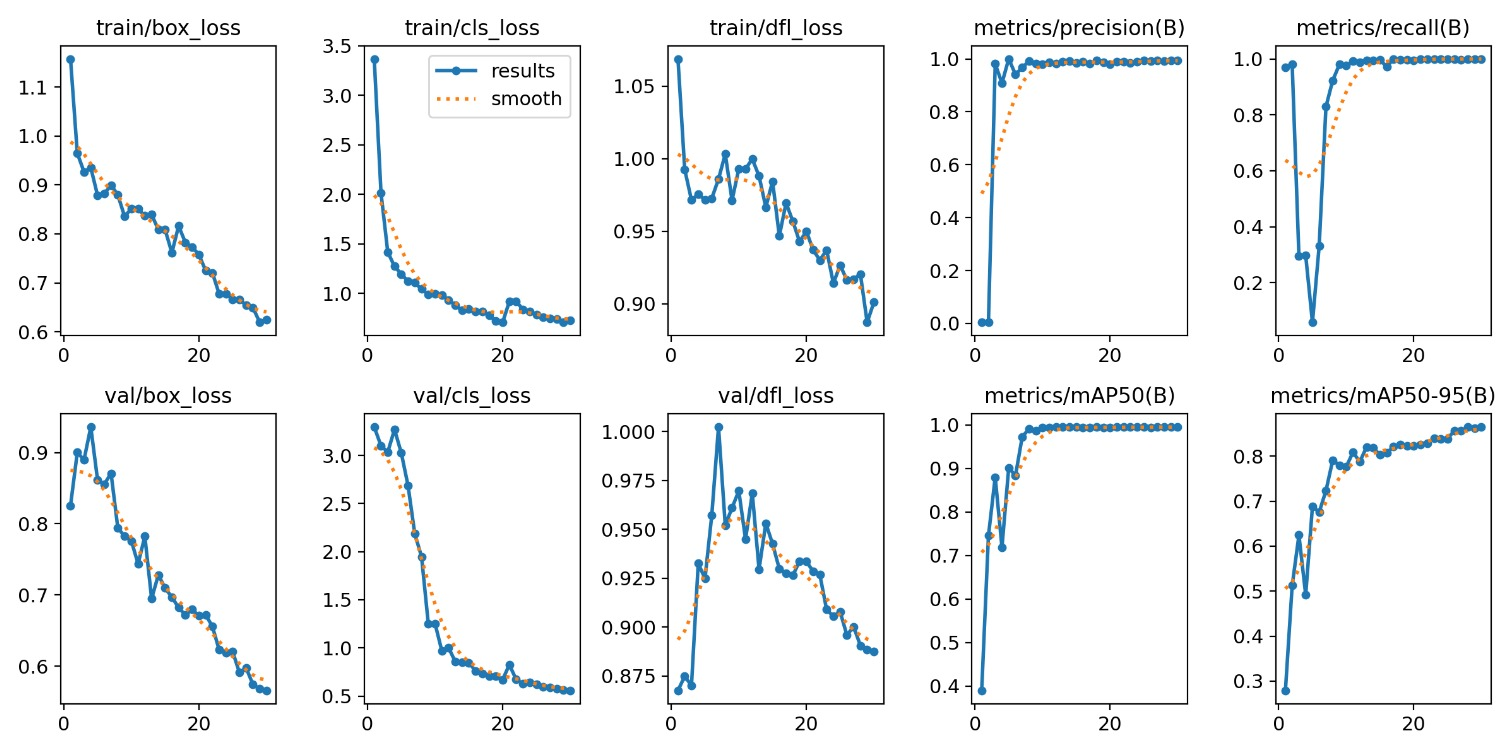
Gráficos de Treinamento
-
Perda por caixa (train/box loss): A perda por caixa é uma medida de quão bem o modelo prediz as localizações das caixas delimitadoras em torno dos objetos nas imagens. Uma perda por caixa menor indica que o modelo está melhorando na localização precisa dos objetos.
-
Perda de classificação (train/cls loss): A perda de classificação é uma medida de quão bem o modelo classifica os objetos nas imagens. Uma perda de classificação menor indica que o modelo está melhorando em identificar os objetos corretos.
-
Perda de localização de recurso (train/dfl loss): A perda de localização de recurso é uma medida de quão bem o modelo localiza os recursos-chave dentro dos objetos nas imagens. Uma perda de localização de recurso menor indica que o modelo está melhorando em identificar os detalhes importantes dos objetos.
-
Precisão (metrics/precision(B)): A precisão é a proporção de objetos detectados pelo modelo que são realmente objetos. Uma precisão maior indica que o modelo está melhorando em detectar apenas objetos reais.
-
Recall (metrics/recall(B)): A recuperação é a proporção de objetos reais que são detectados pelo modelo. Uma recuperação maior indica que o modelo está melhorando em detectar todos os objetos reais nas imagens.
Gráficos de Validação
-
Perda por caixa (val/box loss): A perda por caixa validada é semelhante à perda por caixa de treinamento, mas é calculada em um conjunto de dados de validação diferente que não foi usado para treinar o modelo. Isso ajuda a avaliar o desempenho do modelo em dados não vistos.
-
Perda de classificação (val/cls loss): A perda de classificação validada é semelhante à perda de classificação de treinamento, mas é calculada em um conjunto de dados de validação diferente.
-
Perda de localização de recurso (val/dfl loss): A perda de localização de recurso validada é semelhante à perda de localização de recurso de treinamento, mas é calculada em um conjunto de dados de validação diferente.
-
mAP50 (metrics/mAP50(B)): A mAP50 é uma medida da precisão média do modelo em detectar objetos em diferentes níveis de confiança. Uma mAP50 maior indica que o modelo está melhorando em detectar objetos com precisão.
-
mAP50-95 (metrics/mAP50-95(B)): A mAP50-95 é semelhante à mAP50, mas se concentra em objetos com pontuações de confiança mais altas. Uma mAP50-95 maior indica que o modelo está melhorando em detectar objetos com alta confiança.
4. Resultados
- Resultados do Treinamento: Abaixo, Vídeo 1, o código de teste foi executado e apresentado o resultado do treinamento.
- No vídeo 2, também testamos o código diretamente na Raspberry, após a realização do teste na máquina pessoal. Assim, conseguimos visualizar o resultado obtido.
- No vídeo 3, testamos o modelo em tempo real, onde a contagem acontece a partir do momento que os componentes passam pela linha rosa.
Histórico de Versão
| Data | Versão | Descrição | Autor(es) | Revisor |
|---|---|---|---|---|
| 05/06/2024 | 1.0 | Criação do artefato | Jefferson França e Heitor Marques | Matheus Silverio |
| 08/06/2024 | 1.1 | Adicionando Vídeo 2 | Jefferson França e Heitor Marques | Matheus Silverio |
| 10/07/2024 | 1.2 | Adicionando Vídeo 3 | Jefferson França e Heitor Marques | Matheus Silverio |